👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!
Suno 是一款AI音乐创作工具,可以通过提示词和设置生成一段音乐,而且可以包含歌词和人声 (这非常难得)。在经历了两年探索之后,最近迎来了一次大爆发,也被誉为「音乐圈的 ChatGPT 时刻」。
这是一期关于〖AI音乐〗的主题探索,深度梳理了 Suno 及其创始人 Mikey Shulman 的大量资料,并拓展到AI音乐的发展历程,以及音乐生成大模型的工作原理。
这是我们知道的,关于 Suno 的一切。
希望这份日报的超高信息密度,可以帮你了解 Suno 脚下的土地与仰望的星空,并开始共同期待「写歌像拍照一样简单」的未来。
1. Suno 创业路上的闪光时刻:谁家玉笛暗飞声,散入春风满洛城

🎨 No. 1 前世今生
-
AI与音频的首次结缘,要追溯到遥远的1938年。第一台电子语音合成器 Voder 在贝尔实验室建造成功,标志着电子语音合成技术的诞生。
-
此前,Google、Meta、Stability AI 公司等均发布过AI生成音乐的研究工具,比如 Google DeepMind 推出的人工智能音乐生成模型 Lyria、可以指定歌手风格进行创作的 Dream Track、可以根据文本提示词创作音乐的MusicFX,还有 Meta 推出的使用文本创建音乐的 MediaGen、可以根据文字描述创建声音效果的 AudioGen 等。
-
然而,Suno 横空出世,实现了歌词、人声、乐器、节奏、和声等所有内容的一次性生成,而且歌曲品质非常高,有些完全超出预期 👍 Suno 似乎真正破解了AI音乐的密码。
🎨 No. 2 创业团队
-
Suno 创始人 Mikey Shulman,今年37岁,哈佛大学物理学博士。有些孩子气,总是背着双肩包。喜欢弹钢琴、弹贝斯、弹吉、敲鼓,自认资质一般但依旧迷恋音乐,超级 (!) 喜欢咖啡。
-
Mikey Shulman 和他的三位联合创始人 Georg Kucsko、Martin Camacho、Keenan Freyberg,此前共同任职于AI金融科技创业公司 Kensho,主要工作内容是开发基于AI的语音转录技术。碰巧四人也都是音乐发烧友和音乐家,便开始尝试音频生成技术,并最终全职投入到这一领域。
🎨 No. 3 发展历程
-
2023年4月,Mikey Shulman 他们推出了第一个开源的文本转音频模型 Bark,不仅可以生成语音,还创新地可以生成音乐和哭泣、大笑、叹息等声音效果,一个月之内在 GitHub 狂收 19K Star (现在已经 32K Star 啦) → https://github.com/suno-ai/bark
-
Bark 在架构上受到了 Andrej Karpathy 的 NanoGPT 的启发 → https://github.com/karpathy/nanoGPT
-
随着 Bark 的流行,越来越多的人开始用它生成音乐,这给开发团队留下了深刻印象。
-
2023年7月,他们基于 Bark 开发了一个名为 Chirp 的音乐生成模型,增加了人声音乐功能。
-
2023年9月,发布 Suno Chirp V1,并开始邀请用户加入 Discord 频道体验文字生成音乐。
-
Mikey Shulman 发现,Discord 频道里的用户也在尝试从模型中提取音乐,人们真的渴望使用AI进行音乐创作,这帮助团队明确了方向。
-
2023年12月,Suno 推出网页版;同月与微软达成合作,Suno 插件集成到了微软 Copilot,为更多人所熟知。
-
2024年 2月,Suno 与英伟达合作推出新的音乐模型 Parakeet。
-
2024年3月,Suno 发布 V3,效果提升明显,生成的音乐质量更高、音乐风格与流派更丰富、对 Prompt 理解更准确、幻觉也更少。随着「We Go!」「宫保鸡丁」等作品的快速传播,Suno 终于迎来了爆发,音乐生成领域也出现了「ChatGPT 时刻」。
🎨 No.4 快速破圈
-
Suno 的爆火其实早有预兆。据 a16z 统计,截至2024年1月,全世界最受欢迎的 GenAI 应用 Top 100 里,Suno 是唯一一个上榜的音乐公司。
-
据 Suno CEO 透露,目前用户已经创造出了很多新奇玩法!比如,用 Suno 制作很多歌曲 (片段),各自讲述故事的一部分,然后把它们串起来组成一张迷你音乐专辑 💿
-
Suno 目前支持25种语言,效果比较好的是英语、西班牙语、德语、印地语、普通话和日语,汉语效果也不错,甚至支持粤语、四川话等方言。
🎨 No.5 体验&教程
-
通常一首歌曲包括:前奏 → 主歌 Verse → 导歌 Pre Chorus → 副歌 Chorus → 间奏 → 主歌 → 导歌 → 副歌 → 桥段 → 副歌 → 尾奏。想用 Suno 创作高品质音乐,基础乐理知识和提示词技巧缺一不可 → 指路这篇教程
-
网易云音乐 App 有 Suno 主题歌单,包含歌曲名和歌词,甚至还有 Suno.ai 歌手账户,感兴趣可以前往收听 → https://music.163.com/#/playlist?id=9484842202
2. Mikey Shulman:我有一个梦想,让人们用音乐社交,就像随时随地「拍照晒图」那样

EverydayAI 科技播客在美国超受欢迎,频道主要内容是人工智能在各个领域的实际落地应用,以及对AI热点新闻的真实解读和客观评价。
2月份,Suno AI 创始人 Mikey Shulman 应邀录制 EverydayAI 播客,阐述了 Suno AI 对AI生成音乐 (AI-generated music) 和音乐创作的独到见解,以及公司未来的发展愿景:关于AI音乐,他们有一个梦想——让写歌像拍照一样简单,让听歌像晒图一样有趣。
以下是时间轴
08:40 新工具诞生的意义:Suno 有效弥合了一般用户的音乐能力与创作意愿之间的差距,让所有人都能写一首歌
11:32 音乐创作的未来:GenAI 在音乐创作中具有启发和辅助能力,未来的音乐创作是随时随地和个性化的
14:13 对音乐行业的影响:AI与音乐的合作由来已久,但是 Suno AI 是面向普通用户的,与音乐从业者交集不多
17:48 潜在的版权风险:付费用户保留音乐的所有权,AI生成音乐这一领域的版权法律是复杂且不断变化的
21:39 Suno 现场测验:情人节快到了,现场测试 Suno 的情歌生成能力
30:53 Suno 使用方法:界面、设置、操作、积分、订阅等
以下是让我印象深刻的细节。
-
人类对音乐的喜爱是一种天性,比如我们两岁时随口哼唧着音调,比如快乐时会敲桌子打节拍。只不过现在的音乐创作门槛被拉得太高,又或者普通人实在不善于清晰地描述感受。
-
而 Suno 想激发普通人的这部分热情,借助AI填平情感和音乐作品之间的沟壑,进而让每个人都能创作专属的个性音乐,塑造自己的迷你音乐流派。
-
Suno 将重塑普通人的音乐创作场景:Mikey Shulman 列举了两种理想中的创作场景。第一种是随时随地创作音乐,比如和好友一起去星巴克,朋友那杯 Margoo 咖啡端上来的时候,自己突然想写一首歌,然后5秒内这首曼妙的音乐就生成了,成为此刻的永久纪念;第二种是脑子里有一种旋律,然后通过 Suno 不停地调整和,最终得到了想要的那首音乐。
-
Suno 想做「音乐社交」:日常生活里,人们会随时随地拍照,然后分享给朋友、或者分享到社交平台。其实,人类在音乐方面也有同样的诉求,只是被压制了。Suno 想做的就是让「音乐」成为一种社交载体,所有人随时随地制作音乐,然后分享给三五好友,大家一起欣赏和交流。
-
如何衡量一首音乐的好坏:在评估模型性能时,我们可以设定一些基准测试和量化指标,但是这种评价方式对于复杂多元的现实世界是不可行的。Suno 更看重人们对音乐「美」的感受。如果一定要给有一个判断AI音乐品质的标准,那应该是人类的耳朵吧。
-
其实,超过一半的人用 expert mode:真实数据可能有点出乎意料,Suno 超过一半的用户使用的是更复杂的专业模式 (expert mode),用户愿意花费时间去做调整、做增减、尝试文字、搞即兴,并乐此不疲。
-
生成的音乐是否可以商用:YES。只要是 Suno 的付费用户,音乐生成之后完全可以商用,且所产生的收入与 Suno 无关。之后怎么用都可以,也可以盈利
-
生成的音乐是否有水印:YES。外界可能判断不出来,但是 Suno 公司是可以识别的。
3. 为了让变形金刚 (Transformer) 唱歌,我们真的!费老老老大劲了!

Latent Space 是一个面向AI工程师和从业者的内容社区,2023年以百万级访客的成绩入选美国科技播客排行榜前十,在圈内知名度很高。
Suno 的 CEO Mikey Shulman 完成了与 Latent Space 的一次对谈,非常深度地讨论了音乐生成模型的参数、训练、数据、效果评估、优化方向,以及从开源社区中吸收了哪些宝贵的经验。
这期播客信息量爆炸 💥 得亏 Mikey Shulman 有机器学习专家的技术背景,才能扛得住主持人这么深挖。而且居然把技术核心问题都讲清楚了!!(虽然还是有所保留 😄
另外,Mikey Shulman (或者说 Suno AI) 应该已经把发展路径想得非常清楚了!因为他们明确知道「不做什么」,哪怕否定掉的 solutions 其实是当下其他 AIGC 应用的主流叙事。
Suno 有自己的目的地。🐮🍺
以下是播客时间轴
01:44 音乐生成模型的现状
06:47 人工智能数据的战争与版权
10:32 从金融领域机器学习到音乐创作
12:30 Suno 语音合成起源:Bark 和 Parakeet
16:25 音乐的简易模式与专家模式
21:44 音乐的 Midjourney 时刻
23:43 现场演示
36:00 重制与创作
38:12 Suno 发展方向
41:52 Beyond 单一音轨创作
43:53 最喜欢的 Suno 使用案例
46:00 音频生成领域的2分钟概述
48:42 人工智能的性能基准测试
以下是令人印象深刻的访谈要点:
🎨 No.1 技术架构和行业理解
- TTS (Text to Speech) 技术发展经历的底层架构演变:形式合成 (Formant Synthesis) → 拼接合成 (Concatenative Synthesis) → 基于神经网络的模型 → 调用Eleven Labs 和 OpenAI 的 TTS API,目前的技术已经能够自然、流畅、低延迟地生成各种语音,还可以模仿语调和口音。当前 TTS 技术已经非常成熟,但音乐生成仍有很大的发展空间。
- Mikey Shulman 对音频生成领域的划分: AudioGen = Music + Speech + Sound Effects (SFX),其中:
- Suno = Music + Speech,同类型工具更早可以追溯到 Tensorflow Magenta
- Seamless = translation + speech generation;Audiobox = speech + SFX
- Stable Audio = Music + SFX
🎨 No.2 Suno 借势成长
-
音频领域的「后发优势」:文本生成和图像生成领先了一两年的时间,所以给音频领域留下了大量的经验和教训;换句话说,正是因为发现了音频生成这片「洼地」,Mikey Shulman 他们才欣然决定入场。
-
Suno 的三人行必有我师:从文本领域学到更多,也更相信 Transformer 模型。就像文本生成是训练一个模型,然后预测下一个 token 的概率;音乐生成的原理是类似的,只不过预测的是下一个小段的音频 (the next tiny little bit of audio)。
🎨 No.3 解决方案的独特之处
-
但是音乐生成领域有自己要解决的问题。AI不仅需要理解和模拟复杂的音乐结构、和声、旋律、节奏等元素,还需要让人声和音乐完美结合,这些都是非常大的挑战。Mikey Shulman 在采访中表示,Suno 找了很多新的方法和技巧才走到今天。
-
Suno 找到了创新的解决方案:TTS 训练过程的主要限制是「text to speech」训练数据非常有限,所以 Mikey Shulman 他们另起炉灶,直接在 audio (音频) 数据上进行训练,然后 tweak (调整) 模型使其能执行文本到语音的任务。
- 你可以理解为,他们将音频数据转换成了「tokens」,然后利用这些音频 tokens 进行自监督学习 (self-supervised learning) ,因此 Bark 学到了人类真实音频的各种特征和模式,能够端到端创作出令人震惊的、类似人类的音乐。
-
模型开发过程中如何平更通用性 (general) 和特异性 (specific):类比 GPT 的训练过程,Suno 也选择不强加给模型任何音乐/音频的一般性知识,而是让模型自己学习。也就是说,尽可能少地植入隐含知识。这是一条正确但见效缓慢的路,幸好时间证明这个选择是正确的 (这也解释了 V3 版本有巨大提升的原因)。
-
高质量音乐模型的数据策略:这部分是 Suno 的核心优势所在,不方便说太多 😃 可以稍微透漏一些。
- 一是 Transformer 和文本领域有大量的先进经验,Suno 从中借鉴很多并将继续学习,持续提升可控性和音频保真度等核心指标。
- 二是 Suno 借鉴到了音频分词 (tokenize) 的关键技巧,也就是把音频编码为离散形式,以此确保模型能够产生各种类型的音频,包括语音、背景音乐和人声等。
- 三是 Suno 的训练数据集也不仅仅是音乐,比如添加了非音乐的人声数据集来提升对真实人声的捕捉效果,这借鉴了 Code Llama (开源代码生成模型) 的训练数据集「除了代码还有英语」的宝贵经验,
-
模型尺寸与Scaling law (规模法则):当前 Suno 模型还比较小。因其结构与文本 Transformer 模型类似,所以 Scaling law 应该也是适用的,也就是模型越大、性能越好。不过,Mikey Shulman 分享音频生成大模型很难做到 175B 以上,因为模型每秒输出音频 token 的速度要快,才能保证用户听到的是流畅的音乐 (当然将来可能打脸)。以前受限于时间和计算资源,Suno 团队「被迫」探索了很多提高模型性能的技巧。今后如果一味信奉大力飞砖,那工程团队也就变「懒」了。
🎨 No.4 未来发展
-
Suno 只是拉开序幕,未来有更广阔的星辰大海:目前只能通过文本提示词生成音乐,将来还有很多可能性,比如可以输入声音,可以生成多模态的视频,还可以跟游戏等结合起来 (游戏产业的规模是音乐的50倍)。游戏行业的很多玩法也值得借鉴,比如借鉴 Twitch Plays Pokemon 将人群聚在一起随机生成一场专属音乐会。还可以期待以下 Suno DJ,或者为每个用户量身定制专属的音乐大模型。当前音乐市场不景气,Suno 希望把这个市场激活甚至做大。
-
Suno 目前存在的时长短、咬字不标准 (幻觉)、前后风格不一致 (可控性差) 等问题,都将随着大模型能力的增强而得到解决。另外,文本和图像等领域的现金经验,也会给 Suno 提供可以参考的有价值的经验。
4. 黎明之前:我们在漫长黑夜里踽踽前行,幸好抬头能看见星光

AI技术爆发后,音乐行业的从业者们态度很割裂,有兴奋、有恐惧、有焦虑、也有不以为然。
比较先锋的专业创作者,开始积极探索借助AI技术辅助自己创作。随后,AI逐步渗透到了音乐行业的各个方向,比如声音分离、人声深度伪造、经典创作插件等。音乐创作正式进入AI时代!
这篇文章梳理了AI参与专业音乐制作的技术发展路径,还记录音乐行业大量相关见闻。以下是文章的核心脉络,为了保证阅读流畅度进行了微调。
-
图像生成有 Diffusion,文字生成有 ChatGPT,但是音乐生成模型还没有爬到顶峰 → 目前还没有一个经过大量音频训练的工具,可以接受文本或其他类型的提示,并输出合适的高质量音乐。
-
AI音乐生成模型「难产」的几个原因:① 音频具有相对较高的采样率,每秒钟会产生大量的样本;② 音频数据具有时间维度上的强关联,且难以用文字精准描述;③ 人类的听觉系统异常敏感,对细节要求很苛刻;④ 现有技术生成音频的速度太慢,比如要花一天时间生成一首歌;⑤ 音乐是节奏、和声、音色、歌词的混合体,是一种综合的复杂的感觉,很难精准用文字描述。
-
AI参与音乐创作的方式和程度是循序渐进的:自动化阶段 (提高效率) → MIDI 阶段 (生成旋律和节奏) → Timbre transfer阶段 (创造新声音) → Analog modeling阶段 (精确再现模拟设备特性),AI技术正在逐步改变音乐创作的方式,为音乐家提供新的工具和可能。
-
自动化阶段:音乐人很早就在探索创作的自动化工具,如 iZotope Neutron 4 混音工具、Sonible智能插件等,简化了音乐创作某些环节的流程。因为开发这些工具涉及到的专业知识太过复杂,音频工程师和程序员需要长时间的协作开发。不过,深度学习技术的持续发展,尤其是图像识别领域取得的惊喜突破,给音乐从业者带来了新的期待。
-
MIDI (Musical Instrument Digital Interface,音乐设备数字接口) 阶段:MIDI是一种简化的数据形式,比音频数据更容易处理,因此成为AI音乐创作早期的理想起点。谷歌等公司也在此方向上获得了不错进展。但是,MIDI 只包含了音乐的一部分元素 (如音高和节奏),而没有考虑到音色和声音的质感。更先进的技术亟待出现。
-
Timbre transfer 阶段:Timbre transfer (音色转移) 技术开始出现,也就是将一种音频输入转换成另一种声音特征,例如将人声变为小提琴声。音色转移模型的输出不可预测性,为音乐家的创作提供了丰富新颖的创意。相关插件开始逐步推向市场并参与音乐创作,例如 Holly Herndon 专辑《PROTO》。
-
Analog modeling 建模阶段:Analog modeling (模拟模拟) 音频处理技术开始出现,使用数字方法来模拟和再现传统模拟音频设备 (如模拟合成器、磁带机、均衡器、压缩器等) 的声音特性和行为。更进一步的,有些公司开始使用深度学习方法来进行这类模拟,并实现了更真实的声音效果。也就是说,在AI的帮助下,人们已经可以创造一个全新的、独特的声音了。
文章结尾,作者预测一种类似 Stable Diffusion 或者 ChatGPT 的通用音乐模型即将诞生,并会因此彻底改变人类创作音乐的逻辑。
这篇文章写于2023年5月。四个月后,Suno 上线 Discord;十个月后,Suno 风靡全球。作者预测的变化真的来了。
5. 罗马不是一天建成的:在 Suno AI 出现之前,人类已经搭了很多脚手架

从「抽样」「声音克隆」到「生成式AI」,技术不断演变进化,终于让「人人都可以成为音乐家」变得触手可及。所有人几乎已经共识,音乐行业一定会出现一个类似 Stable Diffusion 或 ChatGPT 这样的应用,并将希望寄托在 Google 和 Stability AI 身上。
只是那时谁也不会想到,正在 GitHub 疯狂收割 Star 的 Bark 模型,就是他们寻觅的那个未来。
🎨 采样:将现有的声音片段融入到音乐作品
-
Synthesizer V:由Dreamtonics开发的合成器插件,可以根据MIDI音符和歌词生成具有特定特征的声音。例如,用户可以选择不同的声音库 (如Natalie) ,用于生成具有特定音色和表达力的合成声音。
-
FakeYou (或类似工具) :提供文本到语音功能,允许用户选择著名说唱歌手和歌手的声音进行合成。例如,Jaymie Silk 使用该工具创作了 Rub Music Vol. 1 EP,其中包含了像 The Weeknd、Kendrick Lamar 和 Tupac 等艺术家的「样本」声音,名噪一时,不过很快就因为版权问题等原因下架了。
🎨 声音克隆:人工智能技术发展的分支,是「音色转移技术」的表亲
- ElevenLabs:一家声音克隆AI公司,能够将一种声音转换成另一种声音,例如火出圈的把 Leonardo DiCaprio 的声音转换成了 Bill Gates、Joe Rogan 的声音。相较于采样技术难以去除的嘶嘶声,使用AI技术克隆的声音已经有了更高的品质。
🎨 生成式AI :使用AI技术来创造全新的声音和音乐作品
-
AIVA:一个AI音乐作曲平台,允许用户通过选择不同的风格和子风格来生成音乐作品;AIVA 适合生成公式化的、功能性的音乐 (但是复杂音乐还不太行) → https://www.aiva.ai
-
Boomy:一个AI音乐创作平台,帮助没有音乐制作经验的用户在几秒钟内完成原创歌曲;已经生成了约 1300 万首歌曲,许多创作者通过将作品上传到 Spotify 平台获得了收益 → https://boomy.com
-
Google MusicLM:Google 开发的一个高级文本到音乐模型,能够根据文本提示生成音乐片段,被寄予厚望。
-
HarmonAI:与 Stability AI 关联的音乐团队,正在开发类似于 Stable Diffusion 模型的音乐版本。
-
Riffusion:一个AI音乐生成工具,基于更成熟的文本到图像技术,通过「微调」Stable Diffusion 模型于频谱图来生成音乐。艺术家 Patten 使用 Riffusion 生成了大量的音频素材,然后剪辑拼接成了专辑「Mirage FM」,这也是第一张完全由文本到音频AI样本生成的专辑。
🎨 作者还深度探讨了一些音乐相关的话题,我们挑选几个一起看看:
-
音乐生成模型的研发瓶颈之一就是缺少高质量的数据。音乐的商品属性使其很容易引起版权纠纷,正式采购的成本高到无法承受,而靠一些灰色方法又很容易引起版权官司。这是可以解释,为什么音频领域落会明显落后于文本和图像领域。
-
据海外媒体报道,Suno 采用的是与艺术家和音乐家合作创建的「特别委托的数据集」,通过与创作者们积极接触和商议适当的许可协议,Suno 将艺术家的作品完整地整合到了模型里。Suno CEO 在采访里也表示会保护音乐家的权益,可以说在这个问题上找到了双方共赢的答案。
-
声音在人类文化中有着独特的价值。它不仅是个体表达自我和情感的媒介,也是文化传承和社会互动的关键工具。尽管AI技术快速发展,人类歌手短时间内依然很难被取代,因为歌手除了音乐还有个人魅力、艺术表达、情感连接和独特的个性,这些都是AI难以完全复制的。
-
音乐创作的本质没有改变:高价值音乐的创作仍然是困难的,不仅需要高超的技能,还需要灵感,需要运气,需要表达,需要穿透噪音找到真正的听众。AI时代来了,垃圾音乐会变多,玩法会变多,但音乐制作的核心挑战并没有改变。
-
对于 Suno 这种生成式AI的音乐创作方式,音乐圈有一个很形象的名字:Spawning 产卵 😄
-
腾讯音乐已经发布了 1000 多首由人工智能生成声音的歌曲 (WTF??
6. 如果你想探究更深层的技术原理 | AI+音乐的生成技术原理介绍

上面提到了 Google、Meta 和 Stability AI 等头部公司在视频生成、音乐生成等领域的探索。如果你想深入理解它们做了哪些工作,模型的工作原理是什么,可以仔细阅读这篇文章。
作者深度解析了 Google 的 MusicLM、Meta 的 MusicGen 以及 Stability AI 的 Stable Audio 这三个领先的AI音乐生成模型。不仅阐述了它们的技术原理,还讨论了它们面临的挑战,例如音乐与文本之间复杂的一对多关系、数据稀缺问题,以及如何训练模型捕捉音乐与文本之间的细微联系等。
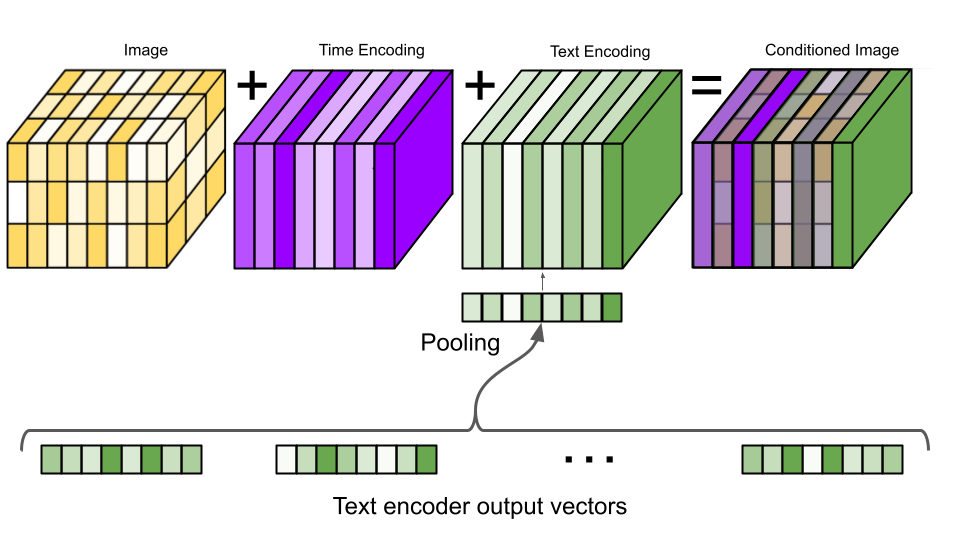
🎨 文本条件化:如何通过文本条件化技术来生成音乐
文本条件化是一种训练模型学习文本和音乐之间关系的方法,使得模型能够根据文本提示生成相应的音乐。
文中提到了 MuLan 和 CLAP 两个模型作为例子,解释了它们是如何工作的,以及它们在训练过程中所面临的挑战,例如音乐与文本之间复杂的一对多关系和数据稀缺问题。

🎨 MusicLM 的架构:Google MusicLM 模型的架构和工作原理
MusicLM 通过三种不同类型的 token 来生成音乐:文本保真 token、长期连贯性 token 和小规模细节 token。每种 token 都由不同的模型生成,并且这些模型在生成过程中相互协作,以产生高质量的音乐输出。
此外,还讨论了 MusicLM 如何整合旋律条件组件,允许用户通过哼唱、唱歌、吹口哨或演奏乐器提供旋律,从而更自然地控制音乐生成。
🎨 旋律提示:MusicLM 如何使用旋律提示来控制生成音乐的轮廓
旋律提示允许用户提供一个旋律,模型将根据这个旋律生成音乐。这种方法提供了比纯文本提示更丰富的音乐创作控制方式,并且可以用于迭代改进模型的输出。
文中还描述了如何通过训练一个联合嵌入模型来实现旋律提示的整合。
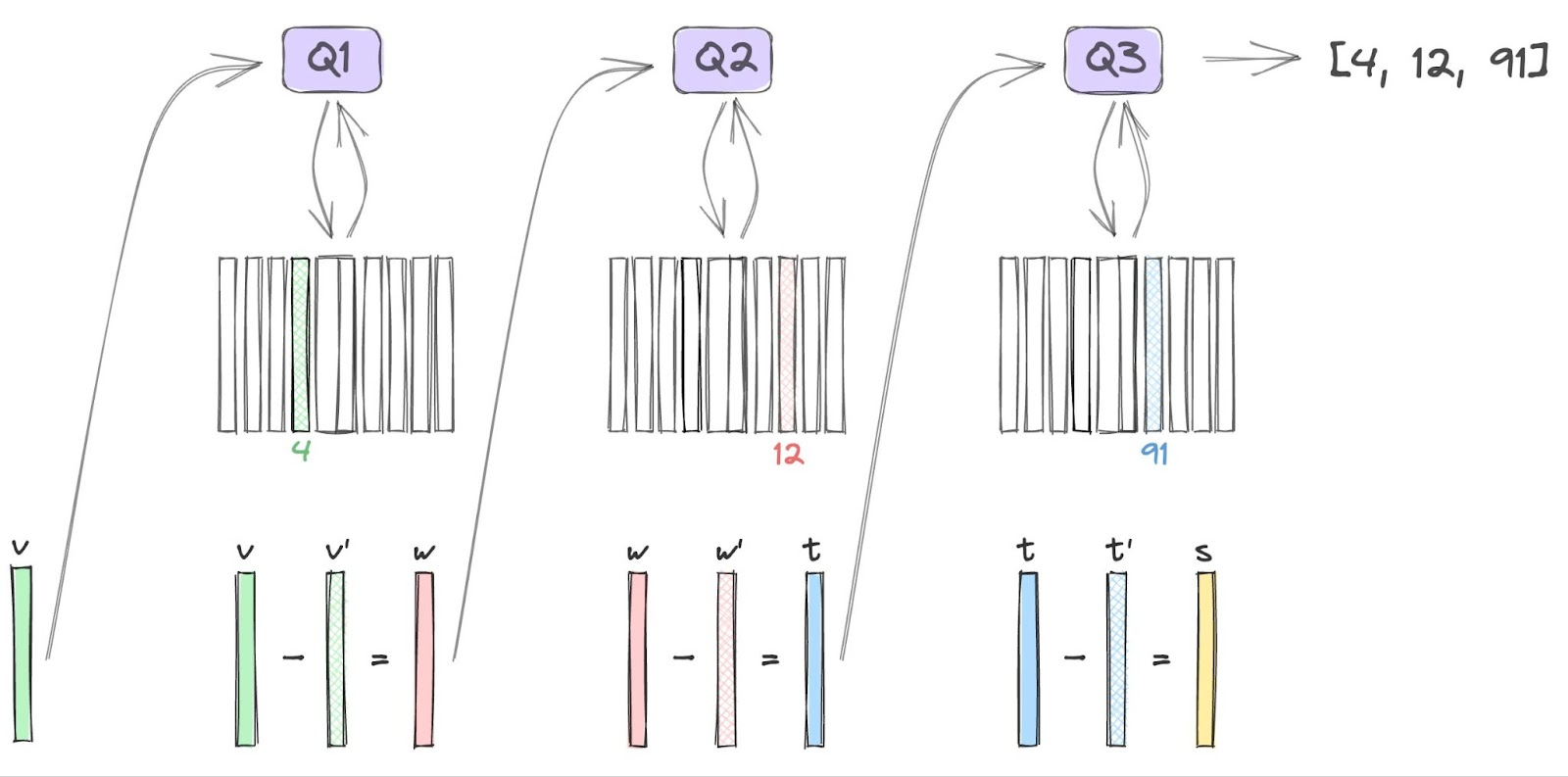
🎨 token 交错模式:在音乐生成中使用的 token 交错模式
这是一种将音频数据表示为一系列 token 的技术。文中提到了几种不同的 token 交错模式,包括并行模式、展平模式、VALL-E 模式和延迟模式,并比较了它们的性能和计算成本。
这部分还强调了 MusicGen 模型如何通过单阶段变换器和高效的 token 交错模式简化音乐生成过程。
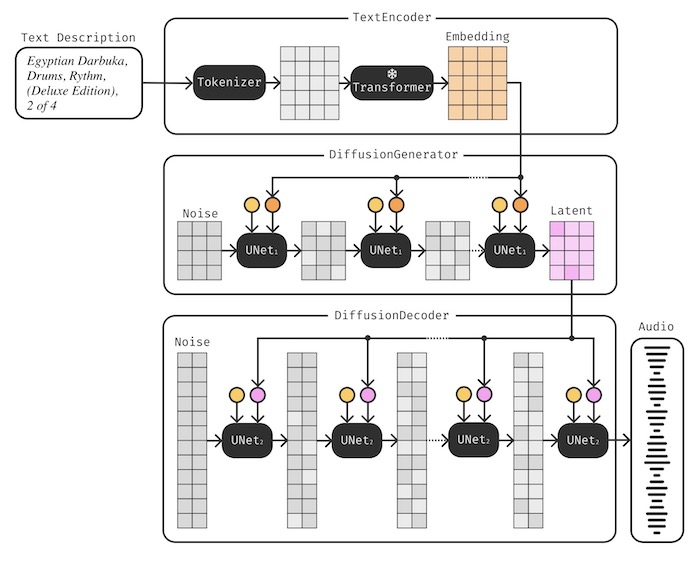
🎨 时间条件化:Stable Audio 如何通过时间条件化来生成不同长度的音频
table Audio使用变分自编码器 (VAE) 将音频转换为嵌入,并在训练过程中引入了时间和起始时间参数,使得模型能够生成指定长度的音频。
这部分详细解释了时间条件化的工作机制和它如何允许系统创建任意长度的音频输出。
🎨 总结AI音乐生成技术的现状和未来趋势。
虽然当前的模型在生成较长音频和清晰再现声音元素方面存在挑战,但行业正在朝着商业部署这些系统的方向前进。或许,不久的将来,我们就可以看到更多激动人心的进步。
Sources
https://www.rollingstone.com/music/music-features/suno-ai-chatgpt-for-music-1234982307/
https://www.theverge.com/24103840/generative-ai-artwork-suno-music-industry-musicians-copyright
https://www.theregister.com/2024/01/08/copyright_music_ai
https://www.youreverydayai.com/ai-will-allow-us-all-to-make-music-we-enjoy
https://www.latent.space/p/suno
https://www.ableton.com/en/blog/ai-and-music-making-the-state-of-play
https://www.ableton.com/en/blog/ai-and-music-making-part-two-tomorrow-is-the-question
https://www.assemblyai.com/blog/what-ai-music-generators-can-do-and-how-they-do-it
https://mp.weixin.qq.com/s/dzex6I0zep3o9zmQGlaSSA
https://mp.weixin.qq.com/s/RuAeD6NgZcNmkD4Z8YEXyg
https://mp.weixin.qq.com/s/rexiKgZ_ikACXyFvbTPs4Q

◉ 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ 点击 🎡生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!